Within Capsul-IA, the text capsule addresses one of the most common challenges when working with documentation: being able to ask questions in natural language about a set of documents and obtain reliable answers. For this purpose, a RAG (Retrieval-Augmented Generation) type system has been developed, which allows the user to upload their own PDF documents and query them directly, without the need to train a different model for each use case.
Dentro de Capsul-IA, la cápsula de texto aborda uno de los retos más habituales cuando se trabaja con documentación: poder preguntar en lenguaje natural sobre un conjunto de documentos y obtener respuestas fiables. Para ello se ha desarrollado un sistema de tipo RAG (Retrieval-Augmented Generation), que permite al usuario subir sus propios documentos PDF y consultarlos directamente, sin necesidad de entrenar un modelo distinto para cada caso de uso.
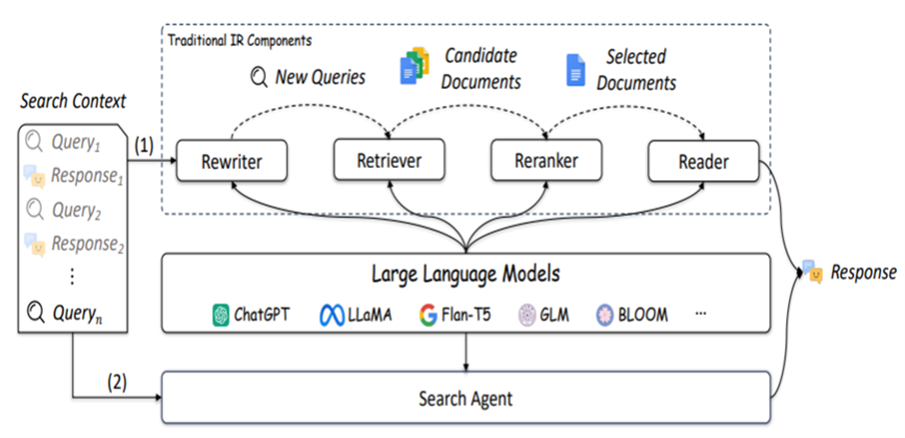
The operation of the capsule is divided into two stages. First, an ingestion phase that is executed only once when uploading each document; and then, a query phase, which is activated every time the user asks a question. In this second phase, the question goes through four blocks that work in a chained manner: query reformulation (rewriter), search for the most similar fragments (retriever), reordering by relevance (reranker), and generation of the final answer (reader). The system is deployed on an NVIDIA Jetson AGX Orin, integrating all these components into a single flow.
El funcionamiento de la cápsula se divide en dos momentos. Primero, una fase de ingestión que se ejecuta una sola vez al subir cada documento; y después, una fase de consulta, que se activa cada vez que el usuario formula una pregunta. En esta segunda fase, la pregunta atraviesa cuatro bloques que trabajan de forma encadenada: reformulación de la consulta (rewriter), búsqueda de los fragmentos más parecidos (retriever), reordenación por relevancia (reranker) y generación de la respuesta final (reader). El sistema se despliega sobre una NVIDIA Jetson AGX Orin, integrando todos estos componentes en un mismo flujo.
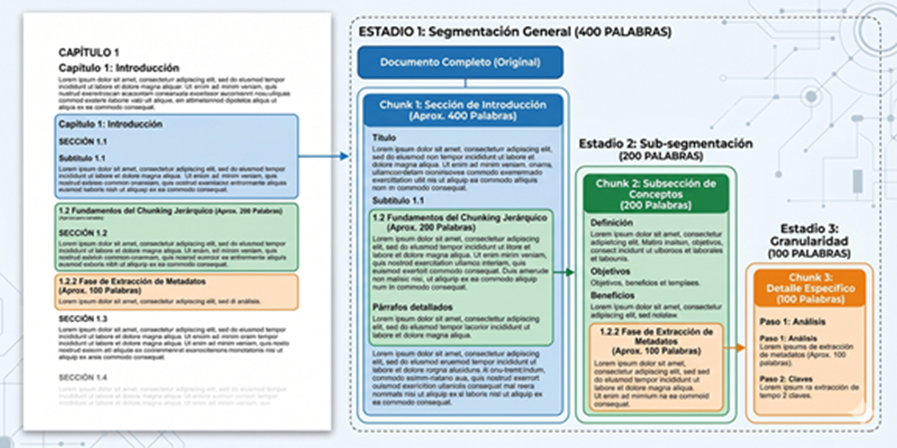
The foundation of the entire system is the way the document is chunked. Unlike the classic approach, which splits the text into fixed-size and independent fragments, the capsule incorporates hierarchical chunking: instead of a flat list of fragments, the document is modeled as a three-level tree (sections, subsections, and paragraphs), and a brief summary generated by a language model is associated with each part. Thus, the system can search with small fragments, which offer greater precision, but automatically return the complete upper block when the necessary information is distributed across several consecutive fragments. In this way, the model always receives an integral context and not loose pieces.
La base de todo el sistema es la forma en que se trocea el documento. En diferencia con el enfoque clásico, que parte el texto en fragmentos de tamaño fijo e independientes la cápsula incorpora un chunking jerárquico: en lugar de una lista plana de fragmentos, el documento se modela como un árbol de tres niveles (secciones, subsecciones y párrafos), y a cada parte se le asocia un breve resumen generado por un modelo de lenguaje. Así, el sistema puede buscar con fragmentos pequeños, que ofrecen mayor precisión, pero devolver automáticamente el bloque superior completo cuando la información necesaria está repartida entre varios fragmentos consecutivos. De este modo, el modelo recibe siempre un contexto íntegro y no trozos sueltos.
At the input of the system operates the rewriter, responsible for bridging the gap between how the user asks and how the document is written. It rewrites the original query into different variants using distinct words, so that even if the user’s question is formulated very differently from how it appears in the text, the reformulations will select the correct document. It is a key component to prevent a relevant document from being discarded simply because it uses specific words.
A la entrada del sistema actúa el rewriter, encargado de eliminar la similitud de entre cómo pregunta el usuario y cómo está redactado el documento. Reescribe la consulta original en diferentes variantes con palabras distintas, de manera que, aunque la pregunta del usuario este formulada de manera muy diferente a como aparece en el texto, las reformulaciones si que elijan el documento correcto. Es una pieza clave para evitar que un documento relevante quede descartado simplemente porque utiliza unas palabras concretas.
Once the candidates are retrieved, they are sent to the reranker, which reorders them based on their actual relevance to the question. The capsule employs two complementary cascaded models: a lightweight and fast one that performs an initial filtering, and a more powerful one that fine-tunes the result on the best candidates. Since both models make different types of errors, they tend to compensate for each other, resulting in a much more precise final selection.
Una vez recuperados los candidatos, estos se envían al reranker, que los reordena según su relevancia real para la pregunta. La cápsula emplea dos modelos complementarios en cascada: uno ligero y rápido que realiza un primer filtrado, y otro más potente que afina el resultado sobre los mejores candidatos. Como ambos modelos cometen tipos de error diferentes, tienden a compensarse mutuamente, lo que se traduce en una selección final mucho más precisa.
The next step in development will be to incorporate a rereader. Its function will consist of refining the retrieved context before delivering it to the generative model, keeping only what is essential to answer. This aims to reduce the noise of irrelevant information, lower the generation cost, and further improve the accuracy of the response.
El siguiente paso del desarrollo será incorporar un rereader. Su función consistirá en depurar el contexto recuperado antes de entregárselo al modelo generador, conservando únicamente lo esencial para responder. Con ello se busca reducir el ruido de la información irrelevante, reducir el coste de generación y mejorar todavía más la precisión de la respuesta.
To objectively measure the effect of all these improvements, the capsule has been evaluated on SQuAD (Stanford Question Answering Dataset), one of the benchmark datasets in reading comprehension. The result has been particularly significant: thanks to the combination of hierarchical chunking, rewriter, and dual reranker, in an initial evaluation the system has achieved an 87% accuracy in the Exact Match metric, surpassing the human baseline published for this dataset, which stands at around 86.8%.
Para medir de forma objetiva el efecto de todas estas mejoras, la cápsula se ha evaluado sobre SQuAD (Stanford Question Answering Dataset), uno de los conjuntos de referencia en comprensión lectora. El resultado ha sido especialmente significativo: gracias a la combinación de chunking jerárquico, rewriter y doble reranker, en una primera evaluación el sistema ha alcanzado un 87 % de aciertos en la métrica Exact Match, superando el umbral humano de referencia publicado para este conjunto, situado en torno al 86,8 %.
These results confirm that the direction taken in the design of the text capsule is the right one. The Capsul-IA team continues working on the definitive version of the system with the goal of delivering a robust, precise conversational solution applicable to real documentation in any domain.
Estos resultados confirman que la dirección tomada en el diseño de la cápsula de texto es la adecuada. El equipo de Capsul-IA continúa trabajando en la versión definitiva del sistema con el objetivo de entregar una solución conversacional robusta, precisa y aplicable a documentación real de cualquier ámbito.
Javier Navarro – Text Capsule, Capsul-IA
![]()
Agradecimientos
Proyecto MIG-20232044, subvencionado por el CDTI – Centro de Desarrollo Tecnológico Industrial, apoyado por el Ministerio de Ciencia e Innovación, y aprobado en la convocatoria para el año 2023 del procedimiento de concesión de ayudas destinadas a “Misiones de Ciencia e Innovación” en el marco de la iniciativa TransMisiones 2023, en el ámbito del Programa Estatal para Catalizar la Innovación y el Liderazgo Empresarial del Plan Estatal de Investigación Científica y Técnica y de Innovación 2021-2023. #PRTR #PlanDeRecuperación # MRR #NextGen #NextGeneration #NextGenerationEU #NGEU #AyudasCDTI

Proyecto PLEC2023-010240 financiado por MICIU/AEI/10.13039/501100011033:








